

 v2.4.0-testnet Hardfork Upgrade Announcement")
GitHub’s chief legal officer, Shelley McKinley, has plenty on her plate, what with legal wrangles around its Copilot pair-progammer, as well as the Artificial Intelligence (AI) Act, which was voted through the European Parliament this week as “the world’s first comprehensive AI law.”
Three years in the making, the EU AI Act first reared its head back in 2021 via proposals designed to address the growing reach of AI into our everyday lives. The new legal framework is set to govern AI applications based on their perceived risks, with different rules and stipulations depending on the application and use-case.
GitHub, which Microsoft bought for $7.5 billion in 2018, has emerged as one of the most vocal naysayers around one very specific element of the regulations: muddy wording on how the rules might create legal liability for open source software developers.
McKinley joined Microsoft in 2005, serving in various legal roles including hardware businesses such as Xbox and Hololens, as well as general counsel positions based in Munich and Amsterdam, before landing in the Chief Legal officer hotseat at GitHub coming up for three years ago.
“I moved over to GitHub in 2021 to take on this role, which is a little bit different to some Chief Legal Officer roles — this is multidisciplinary,” McKinley told TechCrunch. “So I’ve got standard legal things like commercial contracts, product, and HR issues. And then I have accessibility, so [that means] driving our accessibility mission, which means all developers can use our tools and services to create stuff.”
McKinley is also tasked with overseeing environmental sustainability, which ladders directly up to Microsoft’s own sustainability goals. And then there are issues related to trust and safety, which covers things like moderating content to ensure that “GitHub remains a welcoming, safe, positive place for developers,” as McKinley puts it.
But there’s no ignoring that the fact that McKinley’s role has become increasingly intertwined with the world of AI.
Ahead of the EU AI Act getting the greenlight this week, TechCrunch caught up with McKinley in London.

GitHub Chief Legal Officer Shelley McKinley Image Credits: GitHub
Two worlds collide
For the unfamiliar, GitHub is a platform that enables collaborative software development, allowing users to host, manage, and share code “repositories” (a location where project-specific files are kept) with anyone, anywhere in the world. Companies can pay to make their repositories private for internal projects, but GitHub’s success and scale has been driven by open source software development carried out collaboratively in a public setting.
In the six years since the Microsoft acquisition, much has changed in the technological landscape. AI wasn’t exactly novel in 2018, and its growing impact was becoming more evident across society — but with the advent of ChatGPT, DALL-E, and the rest, AI has arrived firmly in the mainstream consciousness.
“I would say that AI is taking up [a lot of] my time — that includes things like ‘how do we develop and ship AI products,’ and ‘how do we engage in the AI discussions that are going on from a policy perspective?,’ as well as ‘how do we think about AI as it comes onto our platform?’,” McKinley said.
The advance of AI has also been heavily dependent on open source, with collaboration and shared data pivotal to some of the most preeminent AI systems today — this is perhaps best exemplified by the generative AI poster child OpenAI, which began with a strong open-source foundation before abandoning those roots for a more proprietary play (this pivot is also one of the reasons Elon Musk is currently suing OpenAI).
As well-meaning as Europe’s incoming AI regulations might be, critics argued that they would have significant unintended consequences for the open source community, which in turn could hamper the progress of AI. This argument has been central to GitHub’s lobbying efforts.
“Regulators, policymakers, lawyers… are not technologists,” McKinley said. “And one of the most important things that I’ve personally been involved with over the past year, is going out and helping to educate people on how the products work. People just need a better understanding of what’s going on, so that they can think about these issues and come to the right conclusions in terms of how to implement regulation.”
At the heart of the concerns was that the regulations would create legal liability for open source “general purpose AI systems,” which are built on models capable of handling a multitude of different tasks. If open source AI developers were to be held liable for issues arising further down-stream (i.e. at the application level), they might be less inclined to contribute — and in the process, more power and control would be bestowed upon the big tech firms developing proprietary systems.
Open source software development by its very nature is distributed, and GitHub — with its 100 million-plus developers globally — needs developers to be incentivized to continue contributing to what many tout as the fourth industrial revolution. And this is why GitHub has been so vociferous about the AI Act, lobbying for exemptions for developers working on open source general purpose AI technology.
“GitHub is the home for open source, we are the steward of the world’s largest open source community,” McKinley said. “We want to be the home for all developers, we want to accelerate human progress through developer collaboration. And so for us, it’s mission critical — it’s not just a ‘fun to have’ or ‘nice to have’ — it’s core to what we do as a company as a platform.”
As things transpired, the text of the AI Act now includes some exemptions for AI models and systems released under free and open-source licenses — though a notable exception includes where “unacceptable” high-risk AI systems are at play. So in effect, developers behind open source general purpose AI models don’t have to provide the same level of documentation and guarantees to EU regulators — though it’s not yet clear which proprietary and open-source models will fall under its “high-risk” categorization.
But those intricacies aside, McKinley reckons that their hard lobbying work has mostly paid off, with regulators placing less focus on software “componentry” (the individual elements of a system that open-source developers are more likely to create), and more on what’s happening at the compiled application level.
“That is a direct result of the work that we’ve been doing to help educate policymakers on these topics,” McKinley said. “What we’ve been able to help people understand is the componentry aspect of it — there’s open source components being developed all the time, that are being put out for free and that [already] have a lot of transparency around them — as do the open source AI models. But how do we think about responsibly allocating the liability? That’s really not on the upstream developers, it’s just really downstream commercial products. So I think that’s a really big win for innovation, and a big win for open source developers.”
Enter Copilot
With the rollout of its AI-enabled pair-programming tool Copilot three years back, GitHub set the stage for a generative AI revolution that looks set to upend just about every industry, including software development. Copilot suggests lines or functions as the software developer types, a little like how Gmail’s Smart Compose speeds up email writing by suggesting the next chunk of text in a message.
However, Copilot has upset a substantial segment of the developer community, including those at the not-for-profit Software Freedom Conservancy, who called for all open source software developers to ditch GitHub in the wake of Copilot’s commercial launch in 2022. The problem? Copilot is a proprietary, paid-for service that capitalizes on the hard work of the open source community. Moreover, Copilot was developed in cahoots with OpenAI (before the ChatGPT craze), leaning substantively on OpenAI Codex, which itself was trained on a massive amount of public source code and natural language models.
GitHub Copilot Image Credits: GitHub
Copilot ultimately raises key questions around who authored a piece of software — if it’s merely regurgitating code written by another developer, then shouldn’t that developer get credit for it? Software Freedom Conservancy’s Bradley M. Kuhn wrote a substantial piece precisely on that matter, called: “If Software is My Copilot, Who Programmed My Software?”
There’s a misconception that “open source” software is a free-for-all — that anyone can simply take code produced under an open source license and do as they please with it. But while different open source licenses have different restrictions, they all pretty much have one notable stipulation: developers reappropriating code written by someone else need to include the correct attribution. It’s difficult to do that if you don’t know who (if anyone) wrote the code that Copilot is serving you.
The Copilot kerfuffle also highlights some of the difficulties in simply understanding what generative AI is. Large language models, such as those used in tools such as ChatGPT or Copilot, are trained on vast swathes of data — much like a human software developer learns to do something by poring over previous code, Copilot is always likely to produce output that is similar (or even identical) to what has been produced elsewhere. In other words, whenever it does match public code, the match “frequently” applies to “dozens, if not hundreds” of repositories.
“This is generative AI, it’s not a copy-and-paste machine,” McKinley said. “The one time that Copilot might output code that matches publicly available code, generally, is if it’s a very, very common way of doing something. That said, we hear that people have concerns about these things — we’re trying to take a responsible approach, to ensure that we’re meeting the needs of our community in terms of developers [that] are really excited about this tool. But we’re listening to developers feedback too.”
At the tail end of 2022, with several U.S. software developers sued the company alleging that Copilot violates copyright law, calling it “unprecedented open-source software piracy.” In the intervening months, Microsoft, GitHub, and OpenAI managed to get various facets of the case thrown out, but the lawsuit rolls on, with the plaintiffs recently filing an amended complaint around GitHub’s alleged breach-of-contract with its developers.
The legal skirmish wasn’t exactly a surprise, as McKinley notes. “We definitely heard from the community — we all saw the things that were out there, in terms of concerns were raised,” McKinley said.
With that in mind, GitHub made some efforts to allay concerns over the way Copilot might “borrow” code generated by other developers. For instance, it introduced a “duplication detection” feature. It’s turned off by default, but once activated, Copilot will block code completion suggestions of more than 150 characters that match publicly available code. And last August, GitHub debuted a new code-referencing feature (still in beta), which allows developers to follow the breadcrumbs and see where a suggested code snippet comes from — armed with this information, they can follow the letter of the law as it pertains to licensing requirements and attribution, and even use the entire library which the code snippet was appropriated from.
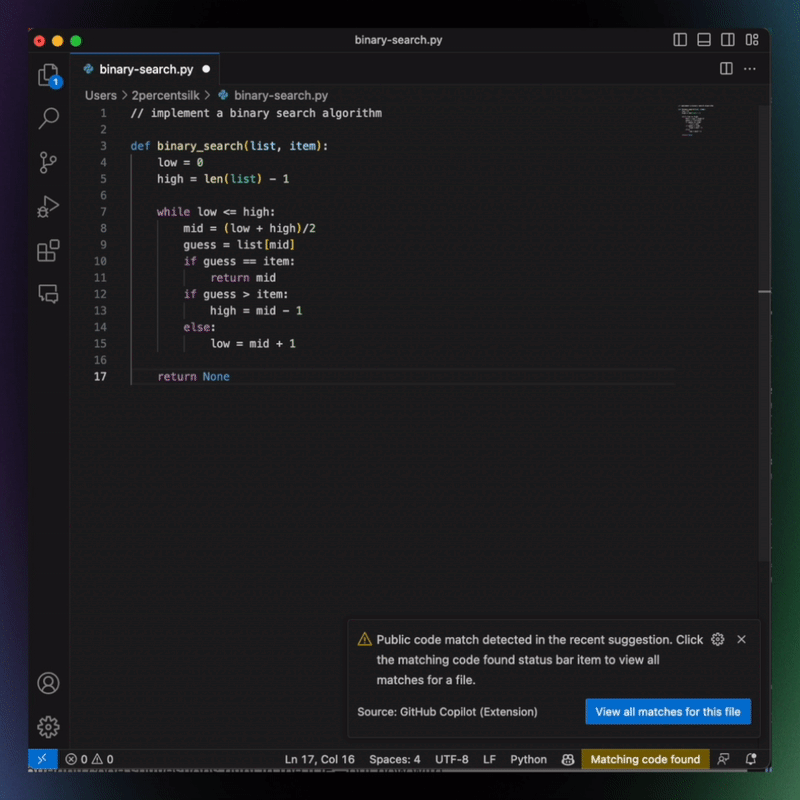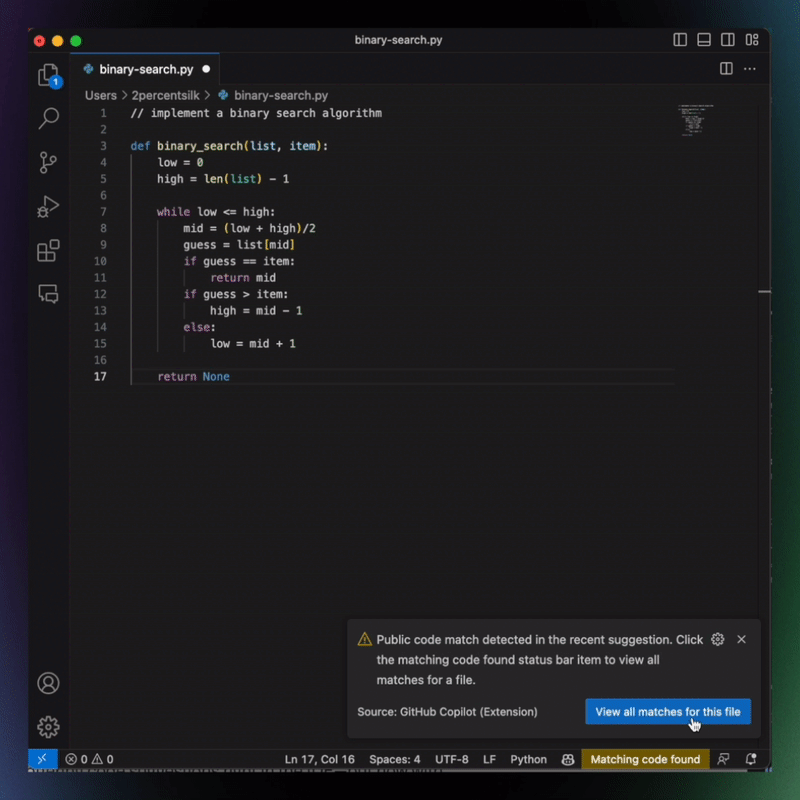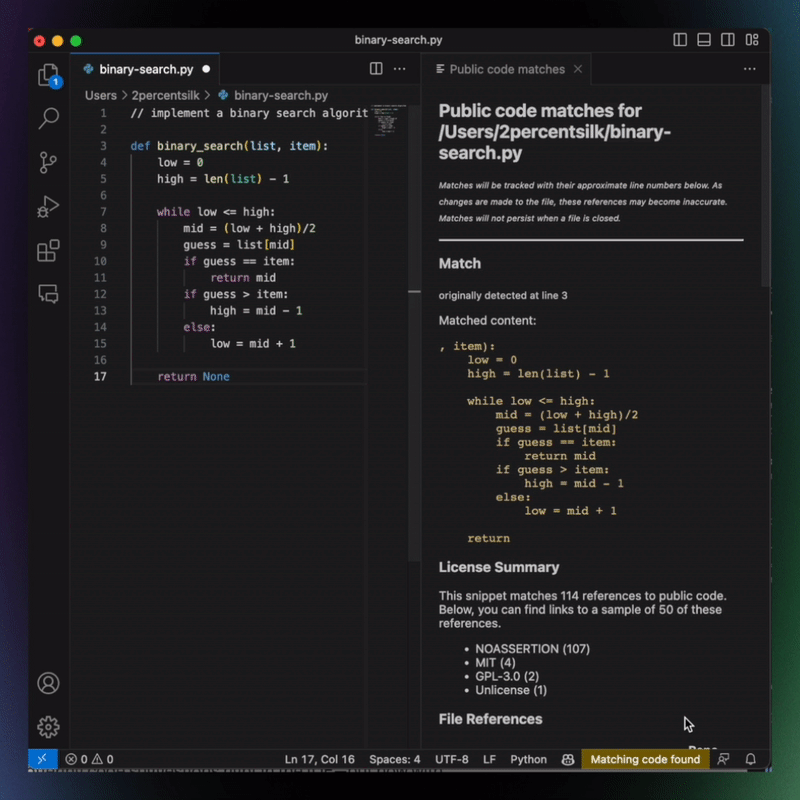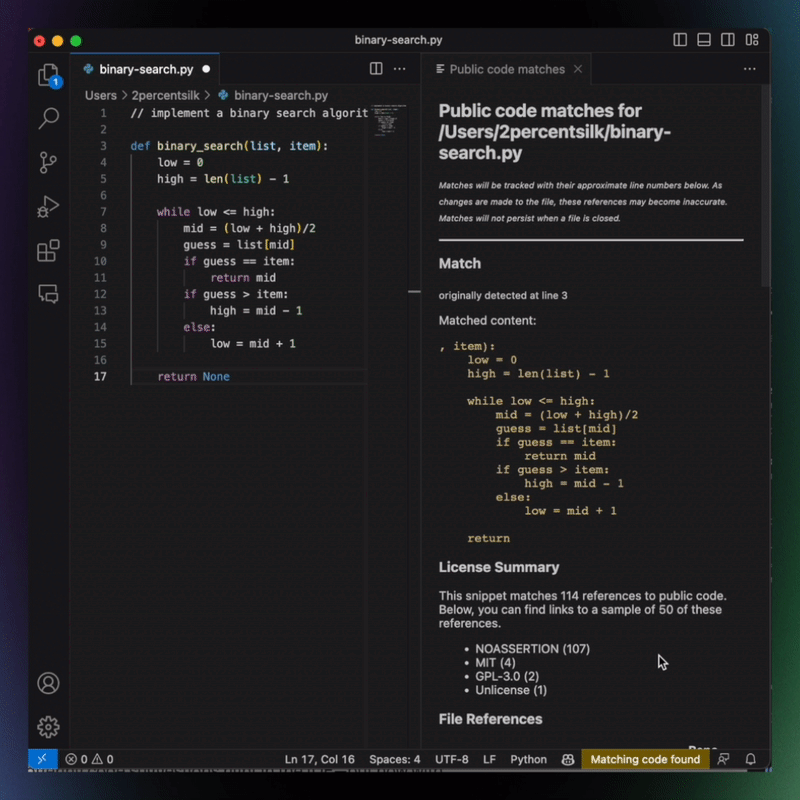
Copilot Code Match Image Credits: GitHub
But it’s difficult to assess the scale of the problem that developers have voiced concerns about — GitHub has previously said that its duplication detection feature would trigger “less than 1%” of the time when activated. Even then, it’s usually when there is a near-empty file with little local context to run with — so in those cases, it is more likely to make a suggestion that matches code written elsewhere.
“There are a lot of opinions out there — there are more than 100 million developers on our platform,” McKinley said. “And there are a lot of opinions between all of the developers, in terms of what they’re concerned about. So we are trying to react to feedback to the community, proactively take measures that we think help make Copilot a great product and experience for developers.”
What next?
The EU AI Act progressing is just the beginning — we now know that it’s definitely happening, and in what form. But it will still be at least another couple of years before companies have to comply with it — similar to how companies had to prepare for GDPR in the data privacy realm.
“I think [technical] standards are going to play a big role in all of this,” McKinley said. “We need to think about how we can get harmonised standards that companies can then comply with. Using GDPR as an example, there are all kinds of different privacy standards that people designed to harmonise that. And we know that as the AI Act goes to implementation, there will be different interests, all trying to figure out how to implement it. So we want to make sure that we’re giving a voice to developers and open source developers in those discussions.”
On top of that, more regulations are on the horizon. President Biden recently issued an executive order with a view toward setting standards around AI safety and security, which gives a glimpse into how Europe and the U.S. might ultimately differ as it pertains to regulation — even if they do share a similar “risk-based” approach.
“I would say the EU AI Act is a ‘fundamental rights base,’ as you would expect in Europe,” McKinley said. “And the U.S. side is very cybersecurity, deep-fakes — that kind of lens. But in many ways, they come together to focus on what are risky scenarios — and I think taking a risk-based approach is something that we are in favour of — it’s the right way to think about it.”
techcrunch.com
