

 v2.4.0-testnet Hardfork Upgrade Announcement")
Over the years, TechCrunch has extensively covered data breaches. In fact, some of our most-read stories have come from reporting on huge data breaches, such as revealing shoddy security practices at startups holding sensitive genetic information or disproving privacy claims by a popular messaging app.
It’s not just our sensitive information that can spill online. Some data breaches can contain information that can have significant public interest or that is highly useful for researchers. Last year, a disgruntled hacker leaked the internal chat logs of the prolific Conti ransomware gang, exposing the operation’s innards, and a huge leak of a billion resident records siphoned from a Shanghai police database revealed some of China’s sprawling surveillance practices.
But one of the biggest challenges reporting on data breaches is verifying that the data is authentic, and not someone trying to stitch together fake data from disparate places to sell to buyers who are none the wiser.
Verifying a data breach helps both companies and victims take action, especially in cases where neither are yet aware of an incident. The sooner victims know about a data breach, the more action they can take to protect themselves.
Author Micah Lee wrote a book about his work as a journalist authenticating and verifying large datasets. Lee recently published an excerpt from his book about how journalists, researchers and activists can verify hacked and leaked datasets, and how to analyze and interpret the findings.
Every data breach is different and requires a unique approach to determine the validity of the data. Verifying a data breach as authentic will require using different tools and techniques, and looking for clues that can help identify where the data came from.
In the spirit of Lee’s work, we also wanted to dig into a few examples of data breaches we have verified in the past, and how we approached them.
How we caught StockX hiding its data breach affecting millions
It was August 2019 and users of the sneaker selling marketplace StockX received a mass email saying they should change their passwords due to unspecified “system updates.” But that wasn’t true. Days later, TechCrunch reported that StockX had been hacked and someone had stolen millions of customer records. StockX was forced to admit the truth.
How we confirmed the hack was in part luck, but it also took a lot of work.
Soon after we published a story noting it was odd that StockX would force potentially millions of its customers to change their passwords without warning or explanation, someone contacted TechCrunch claiming to have stolen a database containing records on 6.8 million StockX customers.
The person said they were selling the alleged data on a cybercrime forum for $300, and agreed to provide TechCrunch a sample of the data so we could verify their claim. (In reality, we would still be faced with this same situation had we seen the hacker’s online posting.)
The person shared 1,000 stolen StockX user records as a comma-separated file, essentially a spreadsheet of customer records on every new line. That data appeared to contain StockX customers’ personal information, like their name, email address, and a copy of the customer’s scrambled password, along with other information believed unique to StockX, such as the user’s shoe size, what device they were using, and what currency the customer was trading in.
In this case, we had an idea of where the data originally came from and worked under that assumption (unless our subsequent checks suggested otherwise). In theory, the only people who know if this data is accurate are the users who trusted StockX with their data. The greater the number of people who confirm their information was valid, the greater chance that the data is authentic.
Since we cannot legally check if a StockX account was valid by logging in using a person’s password without their permission (even if the password wasn’t scrambled and unusable), TechCrunch had to contact users to ask them directly.
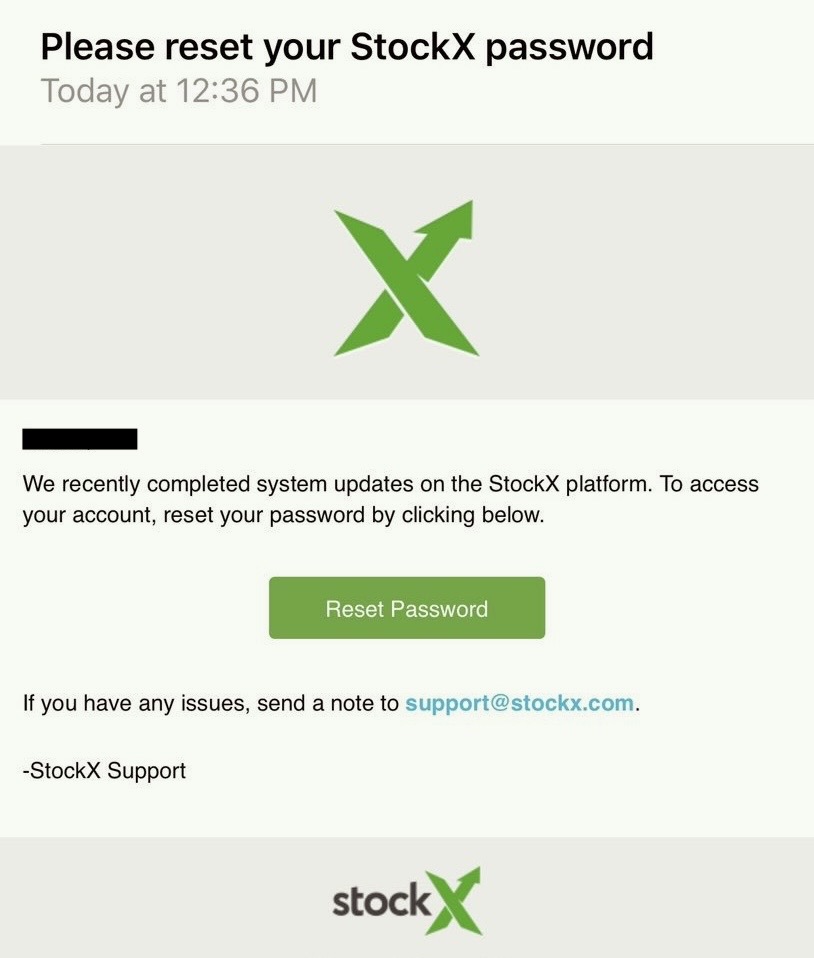
StockX’s password reset email to customers citing unspecified “system updates.” Image Credits: file photo.
We will typically seek out people who we know can be contacted quickly and respond instantly, such as through a messaging app. Although StockX’s data breach contained only customer email addresses, this data was still useful since some messaging apps, like Apple’s iMessage, allow email addresses in place of a phone number. (If we had phone numbers, we could have tried contacting potential victims by sending a text message.) As such, we used an iMessage account set up with a @techcrunch.com email address so the people we were contacting knew the request was truly coming from us.
Since this is the first time the StockX customers we contacted were hearing about this breach, the communication had to be clear, transparent and explanatory and had to require little effort for recipients to respond.
We sent messages to dozens of people whose email addresses used to register a StockX account were @icloud.com or @me.com, which are commonly associated with Apple iMessage accounts. By using iMessage, we could also see that the messages we sent were “delivered,” and in some cases depending on the person’s settings it said if the message was read.
The messages we sent to StockX victims included who we were (“I’m a reporter at TechCrunch”), and the reason why we were reaching out (“We found your information in an as-yet-unreported data breach and need your help to verify its authenticity so we can notify the company and other victims”). In the same message, we presented information that only they could know, such as their username and shoe size that was associated with the same email address we’re messaging. (“Are you a StockX user with [username] and [shoe size]?”). We chose information that was easily confirmable but nothing too sensitive that could further expose the person’s private data if read by someone else.
By writing messages this way, we’re building credibility with a person who may have no idea who we are, or may otherwise ignore our message suspecting it’s some kind of scam.
We sent similar custom messages to dozens of people, and heard back from a portion of those we contacted and followed up with. Usually a selected sample size of around ten or a dozen confirmed accounts would suggest valid and authentic data. Every person who responded to us confirmed that their information was accurate. TechCrunch presented the findings to StockX, prompting the company to try to get ahead of the story by disclosing the massive data breach in a statement on its website.
How we figured out leaked 23andMe user data was genuine
Just like StockX, 23andMe’s recent security incident prompted a mass password reset in October 2023. It took 23andMe another two months to confirm that hackers had scraped sensitive profile data on 6.9 million 23andMe customers directly from its servers — data on about half of all 23andMe’s customers.
TechCrunch figured out fairly quickly that the scraped 23andMe data was likely genuine, and in doing so learned that hackers had published portions of the 23andMe data two months earlier in August 2023. What later transpired was that the scraping began months earlier in April 2023, but 23andMe failed to notice until portions of the scraped data began circulating on a popular subreddit.
The first signs of a breach at 23andMe began when a hacker posted on a known cybercrime forum a sample of 1 million account records of Ashkenazi Jews and 100,000 users of Chinese descent who use 23andMe. The hacker claimed to have 23andMe profile, ancestry records, and raw genetic data for sale.
But it wasn’t clear how the data was exfiltrated or even if the data was genuine. Even 23andMe said at the time it was working to verify whether the data was authentic, an effort that would take the company several more weeks to confirm.
The sample of 1 million records was also formatted in a comma-separated spreadsheet of data, revealing reams of similarly and neatly formatted records, each line containing an alleged 23andMe user profile and some of their genetic data. There was no user contact information, only names, gender, and birth years. But this wasn’t enough information for TechCrunch to contact them to verify if their information was accurate.
The precise formatting of the leaked 23andMe data suggested that each record had been methodically pulled from 23andMe’s servers, one by one, but likely at high speed and considerable volume, and organized into a single file. Had the hacker broken into 23andMe’s network and “dumped” a copy of 23andMe’s user database directly from its servers, the data would likely present itself in a different format and contain additional information about the server that the data was stored on.
One thing immediately stood out from the data: Each user record contained a seemingly random 16-character string of letters and numbers, known as a hash. We found that the hash serves as a unique identifier for each 23andMe user account, but also serves as part of the web address for the 23andMe user’s profile when they log in. We checked this for ourselves by creating a new 23andMe user account and looking for our 16-character hash in our browser’s address bar.
We also found that plenty of people on social media had historical tweets and posts sharing links to their 23andMe profile pages, each featuring the user’s unique hash identifier. When we tried to access the links, we were blocked by a 23andMe login wall, presumably because 23andMe had fixed whatever flaw had been exploited to allegedly exfiltrate huge amounts of account data and wiped out all public sharing links in the process. At this point, we believed the user hashes could be useful if we were able to match each hash against other data on the internet.
When we plugged in a handful of 23andMe user account hashes into search engines, the results returned web pages containing reams of matching ancestry data published years earlier on websites run by genealogy and ancestry hobbyists documenting their own family histories.
In other words, some of the leaked data had been published in part online already. Could this be old data sourced from previous data breaches?
One by one, the hashes we checked from the leaked data perfectly matched the data published on the genealogy pages. The key thing here is that the two sets of data were formatted somewhat differently, but contained enough of the same unique user information — including the user account hashes and matching genetic data — to suggest that the data we checked was authentic 23andMe user data.
It was clear at this point that 23andMe had experienced a huge leak of customer data, but we could not ascertain for sure how recent or new this leaked data was.
A genealogy hobbyist whose website we referenced for looking up the leaked data told TechCrunch that they had about 5,000 relatives discovered through 23andMe documented meticulously on his website, hence why some of the leaked records matched the hobbyist’s data.
The leaks didn’t stop. Another dataset, purportedly on 4 million British users of 23andMe, was posted online in the days that followed, and we repeated our verification process. The new set of published data contained numerous matches against the same previously published data. This, too, appeared to be authentic 23andMe user data.
And so that’s what we reported. By December, 23andMe admitted that it had experienced a huge data breach attributed to a mass scrape of data.
The company said hackers used their access to around 14,000 hijacked 23andMe accounts to scrape vast amounts of other 23andMe users’ account and genetic data who opted in to a feature designed to match relatives with similar DNA.
While 23andMe tried to blame the breach on the victims whose accounts were hijacked, the company has not explained how that access permitted the mass downloading of data from the millions of accounts that were not hacked. 23andMe is now facing dozens of class-action lawsuits related to its security practices prior to the breach.
How we confirmed that U.S. military emails were spilling online from a government cloud
Sometimes the source of a data breach — even an unintentional release of personal information — is not a shareable file packed with user data. Sometimes the source of a breach is in the cloud.
The cloud is a fancy term for “someone else’s computer,” which can be accessed online from anywhere in the world. That means companies, organizations and governments will store their files, emails, and other workplace documents in vast servers of online storage often run by a handful of the Big Tech giants, like Amazon, Google, Microsoft, and Oracle. And, for their highly sensitive customers like governments and militaries, the cloud companies offer separate, segmented and highly fortified clouds for extra protection against the most dedicated and resourced spies and hackers.
In reality, a data breach in the cloud can be as simple as leaving a cloud server connected to the internet without a password, allowing anyone on the internet to access whatever contents are stored inside.
It happens, and more than you might think. People actually find them! And some folks are really good at it.
Anurag Sen is a good-faith security researcher who’s well known for discovering sensitive data mistakenly published to the internet. He’s found numerous spills of data over the years by scouring the web for leaky clouds with the goal of getting them fixed. It’s a good thing, and we thank him for it.
Over the Presidents Day federal holiday weekend in February 2023, Sen contacted TechCrunch, alarmed. He found what looked like the sensitive contents of U.S. military emails spilling online from Microsoft’s dedicated cloud for the U.S. military, which should be highly secured and locked down. Data spilling from a government cloud is not something you see very often, like a rush of water blasting from a hole in a dam.
But in reality, someone, somewhere (and somehow) removed a password from a server in this supposedly highly fortified cloud, effectively punching a huge hole in this cloud server’s defenses and allowing anyone on the open internet to digitally dive in and peruse the data inside. It was human error, not a malicious hack.
If Sen was right and these emails proved to be genuine U.S. military emails, we had to move quickly to ensure the leak was plugged as soon as possible, fearing that someone nefarious would soon find the data.
Sen shared the server’s IP address, a string of numbers assigned to its digital location on the internet. Using an online service like Shodan, which automatically catalogs databases and servers found exposed to the internet, it was easy to quickly identify a few things about the exposed server.
First, Shodan’s listing for the IP address confirmed that the server was hosted on Microsoft’s Azure cloud specifically for U.S. military customers (also known as “usdodeast“). Second, Shodan revealed specifically what application on the server was leaking: an Elasticsearch engine, often used for ingesting, organizing, analyzing and visualizing huge amounts of data.
Although the U.S. military inboxes themselves were secure, it appeared that the Elasticsearch database tasked with analyzing these inboxes was insecure and inadvertently leaking data from the cloud. The Shodan listing showed the Elasticsearch database contained about 2.6 terabytes of data, the equivalent of dozens of hard drives packed with emails. Adding to the sense of urgency in getting the database secured, the data inside the Elasticsearch database could be accessed through the web browser simply by typing in the server’s IP address. All to say, these military emails were incredibly easy to find and access by anyone on the internet.
By this point, we ascertained that this was almost certainly real U.S. military email data spilling from a government cloud. But the U.S. military is enormous and disclosing this was going to be tricky, especially during a federal holiday weekend. Given the potential sensitivity of the data, we had to figure out quickly who to contact and make this their priority — and not drop emails with potentially sensitive information into a faceless catch-all inbox with no guarantee of getting a response.
Sen also provided screenshots (a reminder to document your findings!) showing exposed emails sent from a number of U.S. military email domains.
Since Elasticsearch data is accessible through the web browser, the data within can be queried and visualized in a number of ways. This can help to contextualize the data you’re dealing with and provide hints as to its potential ownership.

A screenshot showing how we queried the database to count how many emails contained a search term, such as an email domain. In this case, it was “socom.mil,” the email domain for U.S. Special Operations Command. Image Credits: TechCrunch
For example, many of the screenshots Sen shared contained emails related to @socom.mil, or U.S. Special Operations Command, which carries out special military operations overseas.
We wanted to see how many emails were in the database without looking at their potentially sensitive contents, and used the screenshots as a reference point.
By submitting queries to the database within our web browser, we used the in-built Elasticsearch “count” parameter to retrieve the number of times a specific keyword — in this case an email domain — was matched against the database. Using this counting technique, we determined that the email domain “socom.mil” was referenced in more than 10 million database entries. By that logic, since SOCOM was significantly affected by this leak, it should bear some responsibility in remediating the exposed database.
And that is who we contacted. The exposed database was secured the following day, and our story published soon after.
It took a year for the U.S. military to disclose the breach, notifying some 20,000 military personnel and other affected individuals of the data spill. It remains unclear exactly how the database became public in the first place. The Department of Defense said the vendor — Microsoft, in this case — “resolved the issues that resulted in the exposure,” suggesting the spill was Microsoft’s responsibility to bear. For its part, Microsoft has still not acknowledged the incident.
To contact this reporter, or to share breached or leaked data, you can get in touch on Signal and WhatsApp at +1 646-755-8849, or by email. You can also send files and documents via SecureDrop.
techcrunch.com
